
大模型参数规模不断攀升的同时,显存、内存资源紧张与硬件价格持续上涨已经成为整个行业的普遍难题,常规8B参数模型运行就需要16GB显存,庞大的硬件开销让端侧AI落地步履维艰。而一项仅用三个数值存储模型权重、可节省6倍显存且几乎不削弱性能的三值量化技术,近两年掀起了全球性的技术竞赛。如今面壁智能联合多方推出的BitCPM-CANN方案,依托华为昇腾算力完成技术落地,让国产技术在这条前沿赛道上实现关键性突破。

想要理解这项技术的价值,首先要搞清楚三值量化的核心逻辑。传统大模型采用高精度格式存储权重,数值选择范围多达数万种,虽然保障了模型表现,却也极大占用硬件空间。三值量化也就是1.58-bit技术,直接将权重数值压缩为三种选择,好比把细节丰富的全彩照片简化为黑白灰三色图案,直观来看很容易让人担心模型性能大幅下滑。但大量研究证实,大模型权重本身存在大量冗余信息,合理调配三个数值,就能承载模型九成以上的能力。
这项技术并非突发创新,2024年微软率先发布BitNetb1.58,系统验证了三值大模型的可行性,后续又推出迭代版本,海外企业PrismML也推出商用三值模型,全球学术界也纷纷跟进优化技术缺陷。不过在此之前,所有成熟的三值模型训练工作,全都依赖海外GPU完成,国产算力能否支撑整套训练流程,一直是悬而未决的行业疑问。
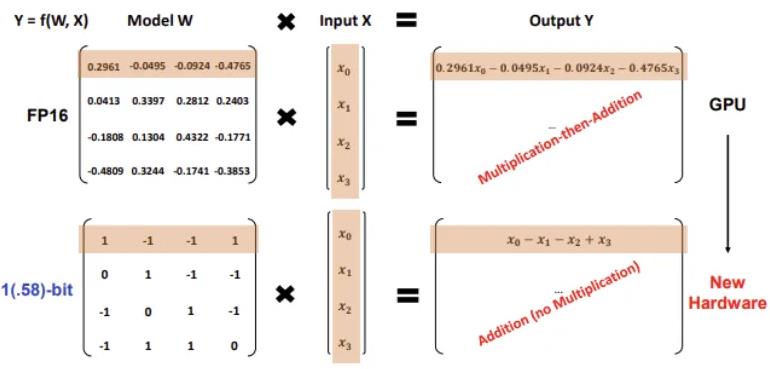
在华为鲲鹏昇腾开发者大会上亮相的BitCPM-CANN,正式给出了国产算力的答案,并且一举创下三项全球首次突破。该系列模型率先在华为昇腾芯片上完成端到端三值大模型训练,打破了海外硬件在这一领域的垄断;同时直接将模型规模拓展至8B参数,推出0.5B、1B、3B、8B四个版本,覆盖手机、电脑等各类端侧设备,突破了国产低比特模型仅能小范围验证的局限。

在性能评测上,研发团队完成了十一项任务、四大类能力的全面对照测试,1B至8B版本的模型能力保留率维持在95.7%至97.2%之间,其中3B版本表现最优,保留率达到97.2%,和同尺寸全精度模型的差距,甚至小于不同全精度模型之间的正常偏差。依托面壁智能成熟的MiniCPM生态,这套模型已全面开源,其社区积累三万多颗星,全网下载量超三千万,绝非停留在纸面的实验成果,开发者可以直接下载部署使用。
6倍显存的缩减效果,让这项技术从实验室走向产业应用,释放出巨大的落地价值。按照实测数据,8B参数全精度模型需要16GB显存,而对应的三值版本显存占用不足3GB,普通手机也能流畅运行。搭配MoE架构优化后,未来8GB内存的手机甚至可以运行600亿参数的大模型。硬件层面也早已做好衔接,高通新款旗舰芯片原生支持2-bit推理,与三值模型完美适配。
当下谷歌、苹果两大手机系统厂商都在全力推进端侧AI布局,端侧智能已经成为移动设备的核心竞争力,而内存不足正是最大的发展瓶颈。放眼整个行业,DRAM、HBM存储芯片价格大幅上涨,硬件成本压力持续加剧,三值量化不再是锦上添花的技术优化,而是行业突破困境的刚需。更重要的是,这项技术也刷新了行业认知,低比特存储并非用性能换取空间的妥协,而是找到了全新的权重知识承载方式,证明传统高精度存储中存在大量可剔除的冗余数据。

如今BitCPM-CANN已经定下清晰的后续发展方向,持续提升模型能力保留率,结合MoE架构拓展模型规模,推动全流程低比特化落地。面壁智能依托国产算力实现三值量化技术落地,不仅补齐了国内在低比特大模型训练领域的短板,也为端侧AI普及扫清了硬件障碍。在全球技术竞赛中,国产技术不再是追随者,而是走出了属于自己的完整路线。随着技术不断迭代,轻量化、高性能的端侧大模型将会全面普及,国产AI产业链也将在这场变革中,牢牢掌握技术发展的主动权。