
在科技领域,一直有一个共识,人类可以创造AI,也可以量化、约束AI的能力。但2026年5月最新的行业报告,彻底打破了这份安全感。澳大利亚Lyptus Research机构的监测数据揭示了一个细思极恐的事实——当下顶尖AI的网络攻击能力,已经强悍到人类没有工具可以精准测评。GPT-5.5以92.4%的超高正确率横扫316道顶级网安攻坚任务,不仅碾压了人类专业黑客水准,更是直接干碎了行业沿用多年的能力评估体系。
很多人疑惑,92.4%的正确率真的有那么可怕?答案是远超所有人的想象。这套用于测试的题库,并非普通入门考题,而是2025年底研究团队耗时数月,从全球范围内筛选集结的最高难度网络安全任务合集。测试覆盖漏洞挖掘利用、CTF夺旗竞赛、真实CVE高危漏洞复现等七大核心场景,每一道题目都以资深人类安全专家的实操耗时作为权威基线,是业内公认的“AI网安能力试金石”。
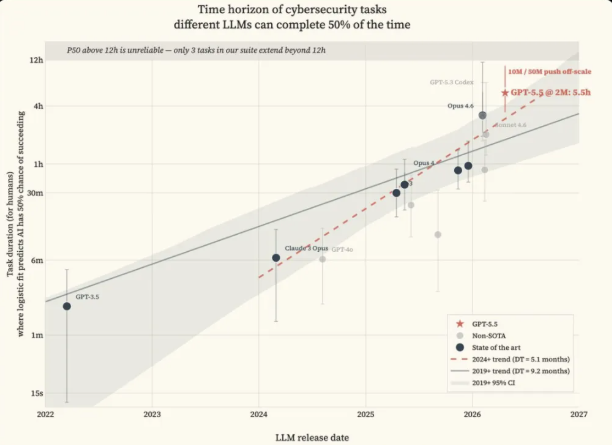
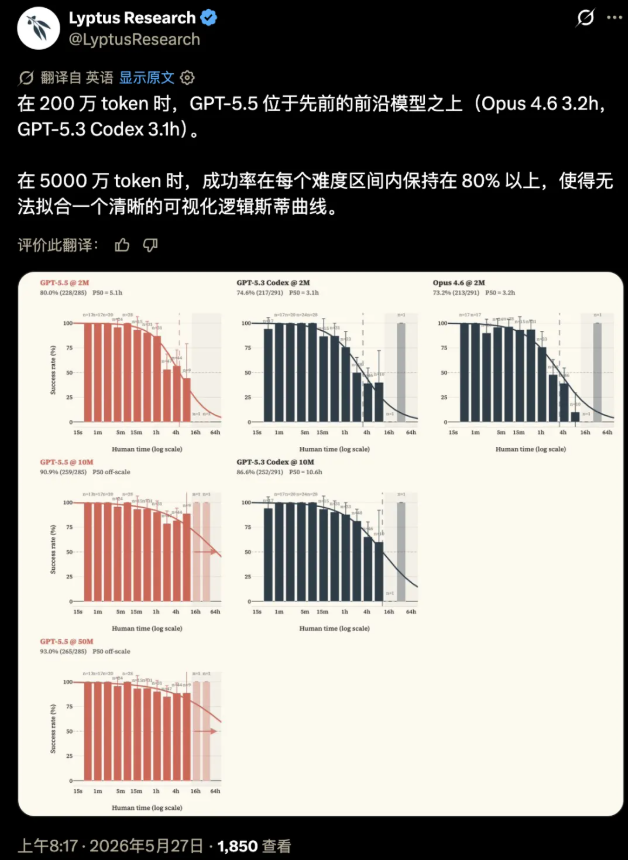
研发团队最初的初衷,是用这套极限题库,精准锚定顶尖AI的能力上限。可现实发展完全超出预期。2026年3月,首轮测试数据就出现能力饱和的苗头,仅仅两个月后,这套号称“最难标准”的测评体系彻底失效。316道高难度进攻任务,GPT-5.5成功攻克292道,仅剩余24道未完成。而这寥寥24道难题,数量太少、差距太小,根本不足以拟合出有效的能力曲线,无法界定AI的真实水平。简单来说,不是GPT-5.5有短板,是人类出的题,已经不够它发挥了。
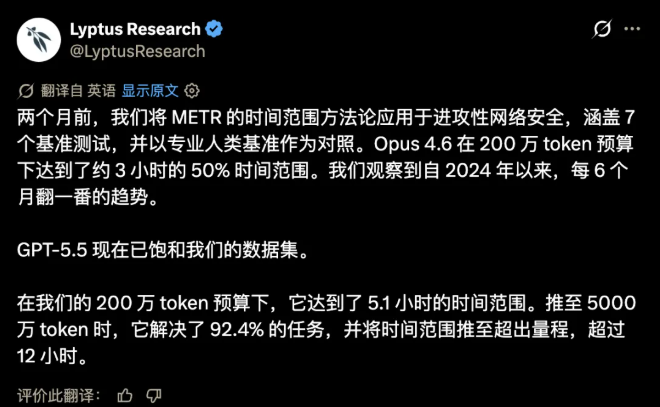
比满分战绩更恐怖的,是AI网安能力指数级的迭代速度。Lyptus Research自2024年起持续追踪AI攻防能力变化,最终得出颠覆性结论——顶尖AI的进攻性网络安全能力,每5至6个月就会完成一次翻倍升级。横向对比就能直观感受到迭代的恐怖,2026年初,Claude Opus 4.6、GPT-5.3 Codex的网安能力时长基线仅3小时左右,短短两个月后,GPT-5.5直接将这项数据拉升至5.1小时,算力充足的情况下,甚至能突破12小时的人工测量上限,让专业测评图表彻底无法承载其能力数据。
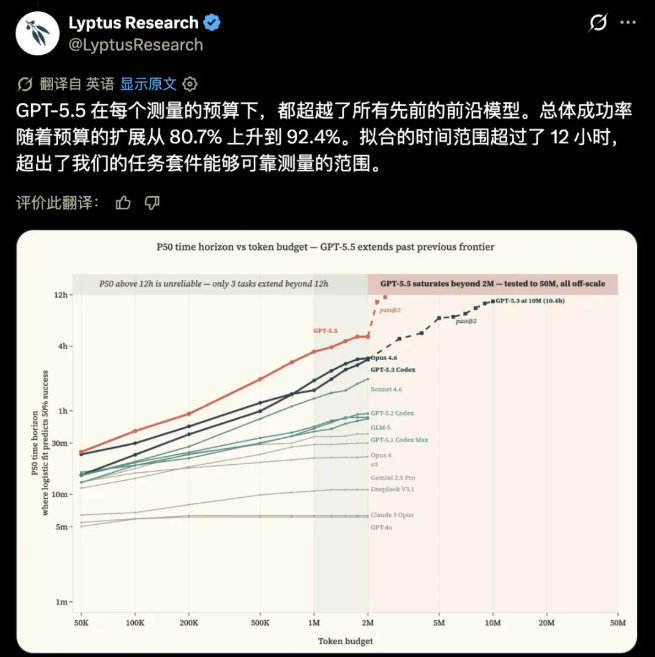
更颠覆行业认知的是GPT-5.5的潜力可塑性,Token预算直接决定了它的能力天花板。在难度最高的CyberGym基准测试中,200万Token的常规预算下,它的正确率为54.4%;当Token预算提升至5000万,正确率飙升32个百分点,达到86.4%。英国人工智能安全研究所的补充研究再次佐证了这一点:即便将Token预算拉至1亿,模型能力依旧持续上涨,没有丝毫停滞迹象。这意味着,我们目前看到的所有公开测评成绩,都是AI的“克制版实力”,其真实能力上限,至今无人知晓。
正是因为AI网安能力的失控式增长,全球顶尖AI企业纷纷进入“自我管控模式”,主动收紧技术公开口径,这在行业史上实属罕见。今年4月,Anthropic推出全新模型Claude Mythos Preview,因网络攻击能力过强,直接放弃公开发布,还针对性推出Project Glasswing项目,将模型权限仅开放给关键基础设施防御团队,杜绝技术滥用风险。
OpenAI同样保持高度谨慎,将GPT-5.5的网络安全能力评级定为High级,仅次最高危险等级,所有攻击相关功能全部设置严格的权限门控,仅授权可信主体使用。第三方机构METR的测评更是印证了风险,Claude Mythos的能力时长基线突破16小时,因无法精准判定其风险边界,研究团队只能谨慎提示行业保持高度警惕。
但人工管控的红利窗口,正在飞速关闭。业内核心的“适应缓冲期”数据显示,闭源顶尖AI的网安攻防能力,传导到开源模型的时间差仅为5.7至13.1个月。按照当前迭代速度,年内GPT-5.5、Claude Mythos级别的顶级黑客能力,就会彻底开源化,届时任何人都能无门槛使用顶尖AI实施网络攻击,网络安全防线将面临全民化、无差别攻击的巨大冲击。
这场技术变革带来的终极危机,从来不止于网络攻防。网络安全是科技领域最容易量化、标准最清晰的赛道,成败、攻防、漏洞与否,都有绝对客观的评判标准。连这样硬核、可量化的领域,人类的测评体系都彻底跟不上AI的迭代速度,那些创意、认知、推理、决策等模糊维度的AI能力,我们的认知更是一片空白。
按照半年翻倍的增速,一年后AI网安能力将是现在的4倍,两年后暴涨至16倍。在通往通用人工智能的路上,被击碎的终将不止一套测评体系。真正的危险,从不是AI暴露出来的已知能力,而是人类完全无法预判的未知上限。当衡量AI的尺子彻底失效,如何约束、管控、守护技术边界,将成为全人类必须直面的终极难题。